Come valutare un Modello di Linguaggio: Benchmark e Metriche più comuni
Se non puoi misurarlo non lo puoi migliorare (Lord Kelvin)
Quando si mette su un bot come il nostro R-Massimo che attinge ad una knowledge base locale per rispondere alle domande, i primi test sono manuali. Si pongono domande al prompt e si cerca di verificare se le risposte ricevute siano o meno coerenti con quanto ci aspettiamo.
Ma questo approccio non è molto scalabile. Se la cosa può funzionare quando il RAG lo facciamo da un breve documento di testo quando invece indicizziamo migliaia di pagine di diversi documenti ovviamente non possiamo più procedere “a occhio”.
Abbiamo affrontato il problema delle metriche in questo articolo precedente, ma ora proviamo a scendere nei dettagli di quello che abbiamo provato.
Ecco alcune metriche
MMLU
- MMLU: Sta per Massive Multitask Language Understanding. Si tratta di un benchmark che valuta la capacità di un modello di intelligenza artificiale di comprendere il linguaggio umano attraverso una vasta gamma di compiti e domini. Include domande provenienti da diverse discipline accademiche, come storia, matematica, scienze, e altro, richiedendo al modello non solo di comprendere il testo, ma anche di applicare conoscenze e ragionamento trasversale.
HumanEval
- HumanEval: È un benchmark che valuta la capacità di programmazione e risoluzione di problemi dei modelli di intelligenza artificiale. HumanEval consiste in una serie di esercizi di programmazione dove al modello viene chiesto di completare funzioni di codice dato un certo numero di test case da superare. Il punteggio, in questo caso il 63.2%, riflette la percentuale di problemi che il modello è stato in grado di risolvere correttamente.
Questi benchmark sono importanti perché offrono un modo per misurare oggettivamente le capacità di un modello di IA in vari domini di comprensione e produzione del linguaggio, oltre a specifiche competenze come il coding. La performance su questi test può dare un’indicazione di quanto sia avanzato un modello e di quali siano le sue potenziali applicazioni pratiche.
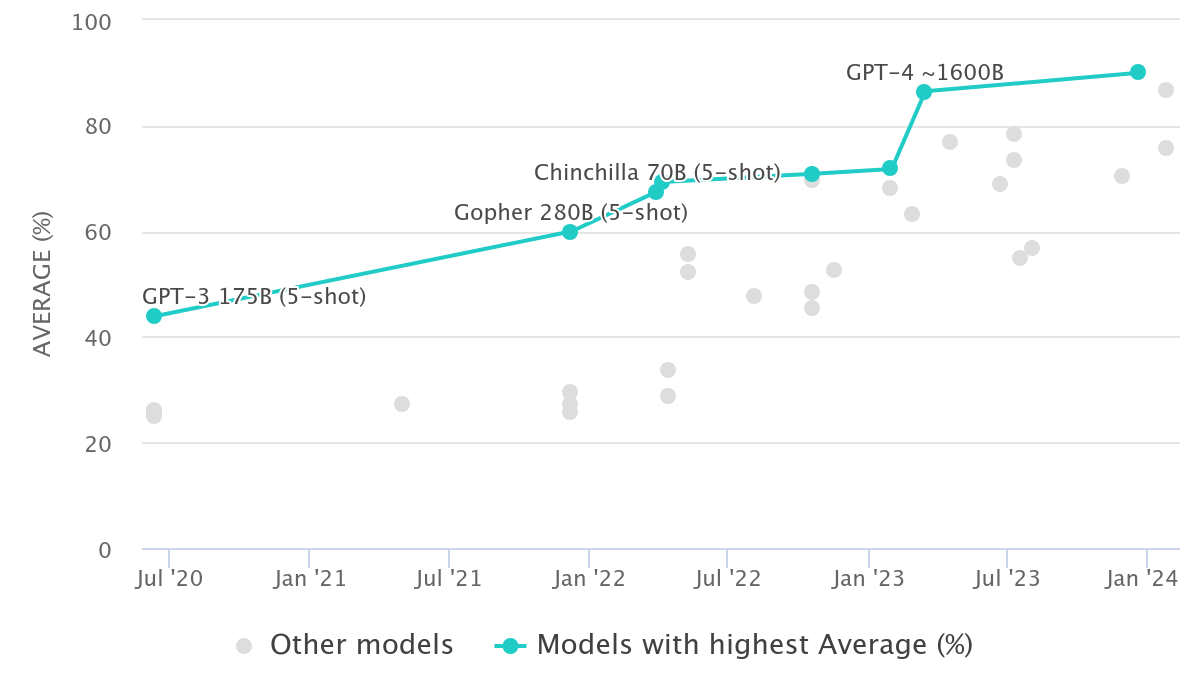 Multi-task Language Understanding on MMLU (source paperswithcode.com)
Multi-task Language Understanding on MMLU (source paperswithcode.com)
Task di Summarization e Metriche
Esistono diversi benchmark specifici per valutare le prestazioni dei modelli di intelligenza artificiale nel task di summarization, ovvero la capacità di sintetizzare e riassumere informazioni da testi lunghi. Questi benchmark sono importanti per misurare quanto accuratamente e fedelmente un modello può condensare il contenuto mantenendo le informazioni chiave e il contesto.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE è forse il più noto e ampiamente utilizzato benchmark per la valutazione del summarization automatico e della traduzione automatica. Include diverse metriche (come ROUGE-N, ROUGE-L, e ROUGE-W) che misurano la sovrapposizione di n-grammi, sequenze di parole, e pesi di parole tra i riassunti prodotti dai modelli e i riassunti di riferimento creati dagli umani.
BLEU (Bilingual Evaluation Understudy)
Anche se originariamente sviluppato per valutare la traduzione automatica, BLEU è stato applicato anche alla valutazione dei riassunti. BLEU misura la precisione degli n-grammi tra il testo generato e il testo di riferimento, penalizzando i riassunti che divergono troppo dai riassunti di riferimento.
METEOR (Metric for Evaluation of Translation with Explicit ORdering)
METEOR è un’altra metrica sviluppata per la traduzione automatica che è stata adattata per valutare il summarization. Considera sinonimi, morfologia e la struttura della frase per fornire una valutazione più flessibile e accurata rispetto a BLEU.
DUC (Document Understanding Conferences)
Le DUC sono state una serie di workshop che hanno fornito dati e benchmark per valutare le prestazioni di sistemi di summarization automatico. Anche se non più attive, le sfide proposte e i set di dati forniti da DUC sono ancora utilizzati come benchmark importanti nel campo.
CNN/Daily Mail
Un dataset ampiamente usato per il training e la valutazione di modelli di summarization automatico. Contiene articoli di notizie con i rispettivi highlights come riassunti, permettendo ai modelli di apprendere come generare riassunti concisi ed informativi.
XSum
Il dataset XSum fornisce un task di summarization estremo, dove l’obiettivo è generare un singolo riassunto di una frase da un documento. Questo benchmark valuta la capacità di un modello di estrarre l’informazione più importante o l’essenza di un articolo.
Come valutare il RAG
La tecnica Retriever-Augmented Generation (RAG) combina la potenza dei modelli di generazione del linguaggio con un sistema di recupero delle informazioni per produrre risposte basate su un vasto corpus di testi. Non esiste un benchmark specifico unicamente per la valutazione dei modelli che utilizzano RAG, poiché la loro performance può essere valutata attraverso una varietà di benchmark esistenti a seconda del compito specifico che il modello RAG è progettato per affrontare, come question answering, summarization, o generazione di testo.
Tuttavia, per valutare l’efficacia di un modello RAG, si possono utilizzare i seguenti approcci e benchmark:
Question Answering Benchmarks
Per i modelli RAG impiegati nel question answering, benchmark come SQuAD (Stanford Question Answering Dataset), Natural Questions, o TriviaQA sono appropriati per valutare la loro capacità di fornire risposte accurate e pertinenti basate sul recupero e sulla comprensione dei testi.
Summarization Benchmarks
Quando i modelli RAG sono applicati al task di summarization, si possono usare benchmark come CNN/Daily Mail, XSum, o ROUGE per valutare la qualità dei riassunti generati in termini di fedeltà, coerenza e concisione.
Generazione di Testo e Altri Compiti
Per altri compiti di generazione di testo, come la generazione di articoli o la composizione di poesie, si possono utilizzare metriche di valutazione quali BLEU, METEOR, o persino valutazioni umane per giudicare la creatività, la coerenza e la rilevanza del testo generato.
Valutazioni Specifiche per RAG
Dal momento che RAG integra la generazione di testo con il recupero delle informazioni, può essere utile valutare separatamente queste due componenti per comprendere meglio le performance del sistema:
- Efficienza del Recupero: Misurare la rilevanza e l’accuratezza delle informazioni recuperate in risposta a una query può aiutare a valutare quanto bene il componente di recupero supporta la generazione di testo.
- Qualità della Generazione: Analizzare la qualità del testo generato (in termini di naturalezza, coerenza, e aderenza alle informazioni recuperate) fornisce insight sulla capacità del modello di integrare efficacemente le informazioni recuperate nel testo generato.
Anche se non esiste un benchmark “one-size-fits-all” specifico per i modelli RAG, la loro performance può essere valutata attraverso una combinazione di benchmark esistenti e metriche di valutazione, a seconda del compito specifico e delle caratteristiche del modello.