Esperimenti con LLM e RAG: Modello in Locale con Mistral e Ollama

Ci siamo lasciati qualche giorno fa con un prototipo costituito da
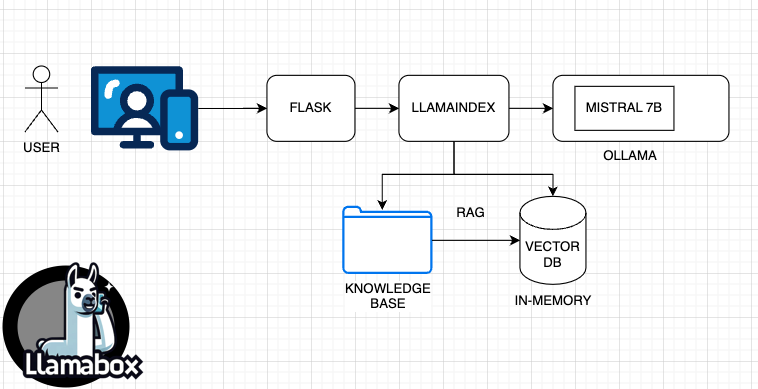
- Flask come server web
- LLamaIndex come libreria per la costruzione del RAG
- le API di OpenAI come “punto” di contatto con il modello GPT4
e naturalmente con gli scritti di Massimo Chiriatti come knowledge base per “aumentare” le conoscenze del modello.
Ma naturalmente l’obiettivo primario era quello di sganciarci completamtnte da OpenAI e avere qualcosa che potesse girare completamente sotto il nostro controllo.
E quindi dovevamo rimpiazzare il client OpenAI con qualcosa che si collegasse ad un modello LLM locale. E abbiamo trovato Ollama.
Cos’è Ollama
Ollama è uno strumento software che ti permette di eseguire modelli di linguaggio di grandi dimensioni (LLMs) direttamente sul tuo computer locale. Questo significa che puoi utilizzare questi modelli senza dover dipendere da un servizio terzo o da un modello di cui non abbiamo il pieno controllo, il che può risultare più conveniente e riservato
L’uso di Ollama è piuttosto semplice. Una volta installato, crea un’API che serve il modello, permettendo agli utenti di interagire direttamente con il modello dal proprio computer locale. Puoi scaricare e avviare modelli utilizzando il comando “run” nel terminale, e se il modello non è installato, Ollama lo scaricherà automaticamente per te. Per esempio, per eseguire il modello Mistal7B, utilizzeresti il comando
ollama run mistral
ed il modello è pronto.
Il risultato: R.Massimo v2
La rimozione di OpenAI ci ha permesso di far girare il modello localmente, per ora ci siamo limitati a Mistral7B, ma presto grazie ad Ollama sperimenteremo modelli più “grossi” come il recente Mixtral di cui abbiamo scritto qui
Questa è l’architettura senza openAI
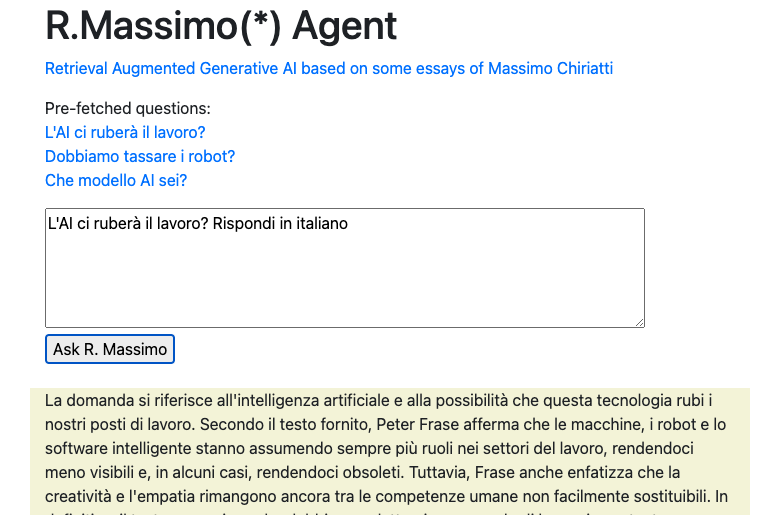
Il prototipo è testabile al nuovo indirizzo (il vecchio sarà rediretto qui)
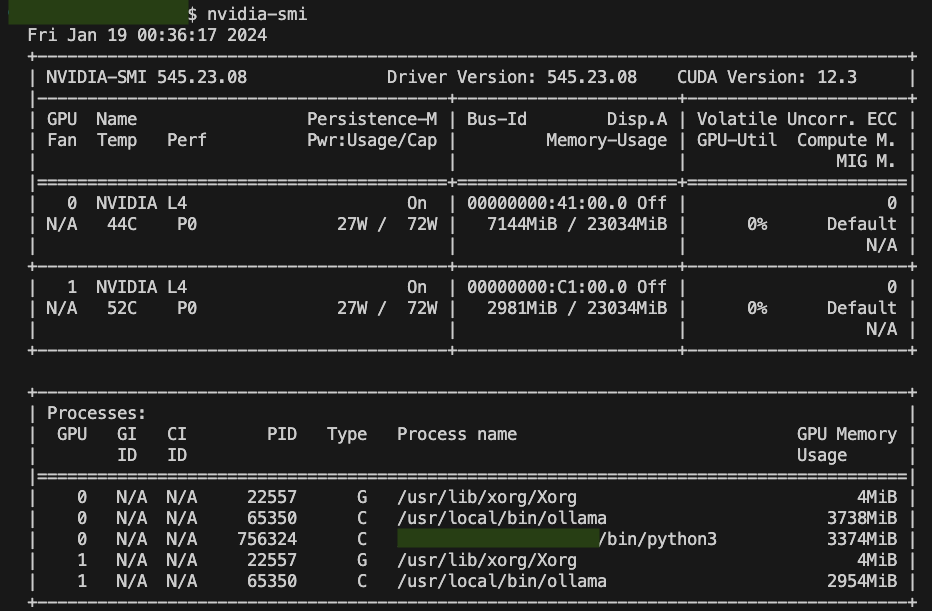
E naturalmente con una certa soddisfazione da nerd ammiriamo i nostri processi impegnare le GPU Nvidia, a riprova che siamo staccati dal cordone ombelicale di Open AI :)
Prossimi step
In realtà rispetto alla versione con Open AI da un punto di vista funzionale non abbiamo veramente aggiunto nulla, e anche come architetturalmente non c’è nessuna vera ottimizzazione. Ci siamo lasciati con una lunga todo list o wish list di cose che vorremmo provare
- usare un modello più grosso del piccolo Mistral-7B
- assicurarci di usare le risorse gpu in modo bilanciato e non avere colli di bottiglia
- metter su una webUI più standard
- mettere un vector DB persistente e non in-memory come quello di default che usiamo ora con Llamaindex.
Tutto questo lo lasciamo alla prossima tappa del nostro laboratorio LLM