Mixtral: Un Nuovo Modello di Linguaggio Basato sul Mix di Blocchi Feed-Forward
E’ stato appena pubblicato un paper dal titolo Mixtral of Experts
- Title: Mixtral of Experts
- Authors: Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed
- Year: 2024
- ePrint: 2401.04088
- Archive Prefix: arXiv
- Primary Class: cs.LG
Come piccola nota patriottica va citato il fatto che questo nuovo modello deriva dal modello Mistral al quale hanno collaborato a vario titolo anche alcune istituzioni italiane come il Cineca che hanno messo a disposizione il supercomputer Leonardo
Cos’è “Mixtral of Experts”?
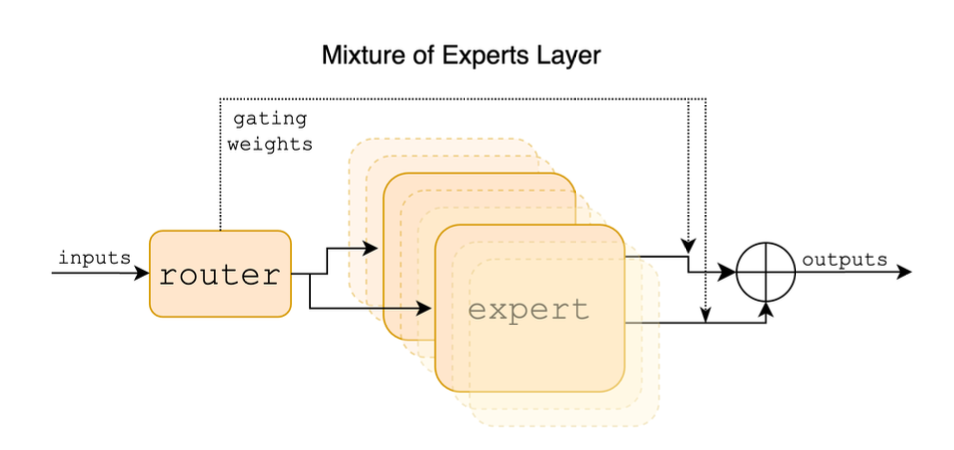
Mixtral of Experts introduce Mixtral 8x7B, un modello di lingua Sparse Mixture of Experts (SMoE). Questo modello, estensione del Mistral 7B, è caratterizzato da strati composti da 8 blocchi feedforward (esperti). Utilizza una rete di instradamento per una lavorazione dinamica, consentendo a ciascun token di accedere a 47B parametri con solo 13B parametri attivi durante l’inferenza. Mixtral eccelle in vari benchmark, superando modelli come Llama 2 70B e GPT-3.5 in matematica, generazione di codice e compiti multilingue. Il modello include anche una versione ottimizzata per l’adempimento di istruzioni, Mixtral 8x7B – Instruct, che offre prestazioni migliorate e pregiudizi ridotti. È disponibile sotto la licenza Apache 2.0.
In Che Modo Mixtral è Diverso da GPT?
Mixtral si differenzia dai modelli tradizionali come GPT nella sua architettura e nell’approccio alla lavorazione dei dati. Come modello Sparse Mixture of Experts (SMoE), Mixtral impiega un meccanismo di instradamento dinamico, attivando diverse parti del modello in base all’input. Elabora ciascun token utilizzando un sottoinsieme di esperti, consentendo l’accesso a un gran numero di parametri mantenendo al contempo costi computazionali inferiori. Al contrario, modelli come GPT utilizzano un’architettura più uniforme con tutti i parametri attivi per ciascun input, portando a una diversa gestione e potenziale performance in compiti specifici.
In Quali Compiti È Stato Misurato Mixtral Rispetto Ad Altri Modelli?
Mixtral è stato valutato rispetto a modelli come Llama 2 70B e GPT-3.5 in compiti che includono:
- Benchmark Comuni: Superando Llama 2 70B e GPT-3.5 nella maggior parte delle metriche.
- Codice e Matematica: Superando significativamente Llama 2 70B.
- Prestazioni Multilingue: Eccellendo in compiti in lingue come francese, tedesco, spagnolo e italiano.
- Benchmark di Pregiudizio: Dimostrando meno pregiudizi e sentimenti più positivi rispetto a Llama 2.
- Adempimento di Istruzioni: Superando GPT-3.5 Turbo, Claude-2.1, Gemini Pro e Llama 2 70B in compiti di adempimento di istruzioni.
Qual È Il Costo Computazionale Misurato Rispetto a Llama o GPT?
L’efficienza computazionale di Mixtral è notevole grazie ai suoi minori parametri attivi durante l’inferenza, utilizzando solo 13B parametri attivi nonostante l’accesso a 47B. Supera o si equipara a Llama 2 70B e GPT-3.5 attraverso vari benchmark utilizzando 5 volte meno parametri attivi. In compiti specializzati come generazione di codice, matematica e trattamento multilingue, Mixtral mostra un’efficienza computazionale superiore senza compromettere le prestazioni.
Che Cos’è Il Rating Elo dell’Arena?
Il sistema di rating Elo dell’Arena calcola i livelli di abilità relativi nei giochi giocatore contro giocatore, in particolare negli scacchi. Assegna valutazioni numeriche ai giocatori, con numeri più alti che indicano giocatori più forti. Il sistema regola queste valutazioni in base all’esito delle partite e alla forza relativa degli avversari. Originariamente progettato per gli scacchi, il sistema di rating Elo è stato adattato per vari altri giochi e sport competitivi.
Mixtral Supera Llama2 e GPT3.5 nel Fine Tuning
In scenari di fine-tuning, Mixtral, in particolare la sua versione Mixtral8x7B–Instruct, è stato confrontanto con GPT-3.5, Llama 2 70B e altri modelli:
- Fine-tuning per comiti specifici: Mixtral8x7B– nstruct supera GPT-3.5 Turbo, Claude-2.1, Gemini Pro e i modelli chat Llama 2 70B nelle valutazioni umane.
- Prestazioni nei Benchmark: Le valutazioni indipendenti mostrano che Mixtral – Instruct raggiunge un rating Elo dell’Arena più alto rispetto ai modelli concorrenti.
- Bias e Sentiment: Mixtral mostra meno pregiudizi e “sentiment” più positivi rispetto a Llama 2 nei benchmark di bias.
Conclusioni
Basandoci sulle affermazioni del paper Mixtral dimostra prestazioni superiori in compiti specializzati e valutazioni umane quando affinato, in particolare per il fine-tuning su task specifici e nelle metriche di bias.