Prompt tuning nei modelli LLM. Perché è più interessante del fine tuning e del prompt engineering
I termini “fine-tuning”, “prompt tuning” e “prompt engineering” sono correlati ma rappresentano tecniche distinte nel contesto dell’adattamento dei modelli di linguaggio. Ecco una spiegazione chiara di ciascuna tecnica e delle loro differenze:
Fine-Tuning
Cos’è:
- Fine-tuning è il processo di addestrare ulteriormente un modello pre-addestrato su un set di dati specifico per un determinato compito o dominio.
Come funziona:
- Si inizia con un modello di base pre-addestrato.
- Si utilizza un set di dati specifico per il compito desiderato per addestrare ulteriormente il modello.
- L’intero modello viene aggiornato per adattarsi meglio ai dati specifici del compito.
Esempio:
- Utilizzare un modello di linguaggio pre-addestrato e addestrarlo ulteriormente su un corpus di testi medici per migliorare le sue capacità di risposta a domande mediche.
Prompt Tuning
Cos’è:
- Prompt tuning è una tecnica che ottimizza specifici parametri di prompt che vengono aggiunti all’inizio dell’input, senza modificare i pesi del modello principale.
Come funziona:
- Si introducono “soft prompts”, ovvero parametri aggiuntivi che fungono da contesto o istruzioni per il modello.
- Questi parametri vengono addestrati per migliorare la performance del modello su un compito specifico.
- Non si modifica il modello principale, ma solo i prompt.
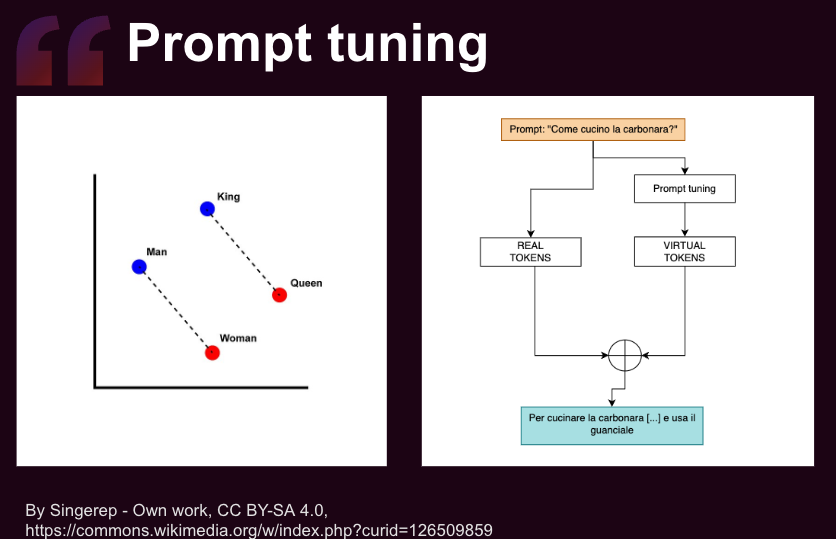
Esempio:
- Aggiungere una serie di parametri di prompt ottimizzati all’inizio di un input per migliorare le risposte di un modello di linguaggio su compiti di traduzione linguistica.
Prompt Engineering

Cos’è:
- Prompt engineering è l’arte di progettare e formulare i prompt di input in modo da ottenere i migliori risultati possibili da un modello di linguaggio pre-addestrato.
Come funziona:
- Si creano prompt dettagliati, specifici e ben strutturati per guidare il modello verso risposte desiderate.
- Si utilizzano vari approcci, come fornire esempi di input-output, utilizzare frasi di avvio specifiche o porre domande in modo strategico.
- Non comporta alcun addestramento o modifica dei pesi del modello.
Esempio:
- Creare un prompt specifico che guida un modello di linguaggio a generare un sommario di un documento scientifico, come: “Riassumi il seguente testo scientifico in modo chiaro e conciso: [Testo]”.
Confronto tra Fine-Tuning, Prompt Tuning e Prompt Engineering
| Caratteristica | Fine-Tuning | Prompt Tuning | Prompt Engineering |
|---|---|---|---|
| Modifica del Modello | Sì (l’intero modello*) | No (solo parametri di prompt) | No |
| Addestramento Necessario | Sì | Sì (ma solo per i prompt) | No |
| Efficienza dei Parametri | Bassa (tutti i parametri) | Alta (pochi parametri) | Molto alta (nessun parametro) |
| Risorse Computazionali | Alte | Moderate | Basse |
| Scalabilità | Minore (ogni compito richiede un modello) | Alta (stesso modello con diversi prompt) | Molto alta (stesso modello, vari prompt) |
| Flessibilità | Bassa | Alta | Molto alta |
(*) Questo non è del tutto corretto, Esiste una categoria di tuning detta LoRa che minimizza il numero di parametri da riaddestrare.
Riassumendo
- Fine-Tuning è ideale per creare modelli altamente specializzati per compiti specifici, ma richiede notevoli risorse computazionali e set di dati specifici.
- Prompt Tuning ottimizza parametri specifici aggiunti come prompt, mantenendo il modello principale invariato, e offre un buon equilibrio tra efficienza e specializzazione.
- Prompt Engineering si basa sulla progettazione intelligente dei prompt di input per guidare il modello, senza richiedere alcun addestramento o modifica dei parametri, risultando estremamente flessibile ed efficiente.
Questi tre approcci possono essere utilizzati in modo complementare a seconda delle esigenze specifiche dell’applicazione e delle risorse disponibili.
Qualche dettaglio sul Prompt Tuning
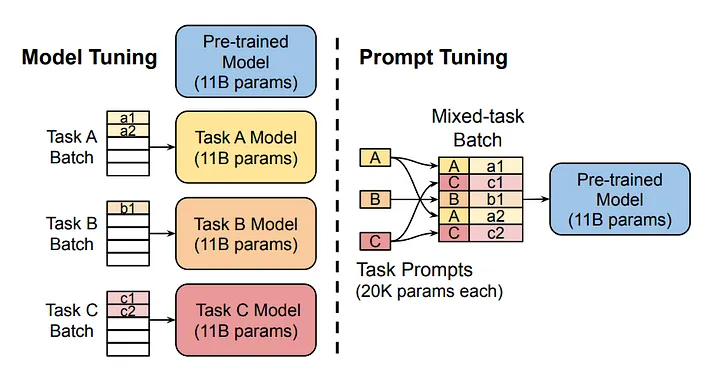
Il diagramma fornisce un confronto tra il tuning tradizionale del modello (Model Tuning) e il tuning dei prompt (Prompt Tuning).
Model Tuning (Lato Sinistro):
- Modello Pre-addestrato:
- Si parte con un modello pre-addestrato (ad esempio, 11 miliardi di parametri).
- Modelli Separati per Ogni Compito:
- Per ogni compito (Compito A, Compito B, Compito C), si crea un modello separato che viene fine-tuned.
- Questo comporta la creazione di Modelli per il Compito A, Compito B e Compito C, ognuno con 11 miliardi di parametri.
- I batch specifici per ogni compito (Batch Compito A, Batch Compito B, Batch Compito C) vengono utilizzati per fine-tuning di questi modelli individuali.
Prompt Tuning (Lato Destro):
- Modello Pre-addestrato:
- Utilizza lo stesso modello pre-addestrato (11 miliardi di parametri) per tutti i compiti.
- Prompt Specifici per il Compito:
- Introduce prompt specifici per il compito (20K parametri ciascuno) per il Compito A, Compito B e Compito C.
- Batch Misto:
- Combina batch di compiti diversi in un batch misto.
- I prompt specifici per ogni compito (A, B, C) guidano il modello pre-addestrato su come gestire gli input specifici del compito (a1, a2, b1, c1, c2).
Punti Chiave Evidenziati dal Diagramma
- Efficienza dei Parametri:
- Model Tuning: Ogni compito richiede un modello fine-tuned separato, portando a ridondanza nei parametri e maggiore carico computazionale.
- Prompt Tuning: Solo i prompt specifici per il compito vengono regolati, mentre il modello pre-addestrato rimane lo stesso per tutti i compiti. Questo riduce significativamente il carico dei parametri.
- Scalabilità:
- Model Tuning: Scalare su più compiti significa dover fine-tuning e memorizzare molteplici modelli di grandi dimensioni.
- Prompt Tuning: Più facile da scalare poiché solo i prompt devono essere memorizzati e regolati, permettendo allo stesso modello di base di gestire vari compiti.
- Flessibilità:
- Model Tuning: Meno flessibile a causa della necessità di mantenere e gestire molteplici modelli.
- Prompt Tuning: Alta flessibilità poiché nuovi compiti possono essere incorporati semplicemente creando e regolando nuovi prompt.
Conclusioni
Il prompt tuning potrebbe essere un approccio più efficiente e scalabile rispetto al tuning tradizionale del modello. Concentrandosi sull’aggiustamento dei prompt specifici per il compito anziché dell’intero modello, il prompt tuning consente un notevole risparmio di risorse computazionali e di archiviazione, mantenendo al contempo alte prestazioni su vari compiti.