BitNet b1.58: una variante di Large Language Models (LLM) a 1 bit
Un nuovo articolo introduce BitNet b1.58, una variante di Large Language Models (LLM) a 1 bit, dove ogni parametro assume valori ternari {-1, 0, 1}, quindi non esattamente 1-bit ma 1.58bit equivalenti per la precisione, raggiungendo prestazioni pari ai modelli full-precision (FP16 o BF16) ma con maggiore efficienza in termini di latenza, memoria, throughput e consumo energetico. Questo modello introduce una nuova legge di scala e apre la strada a un paradigma computazionale innovativo e alla progettazione di hardware specifico ottimizzato per LLM a 1 bit.
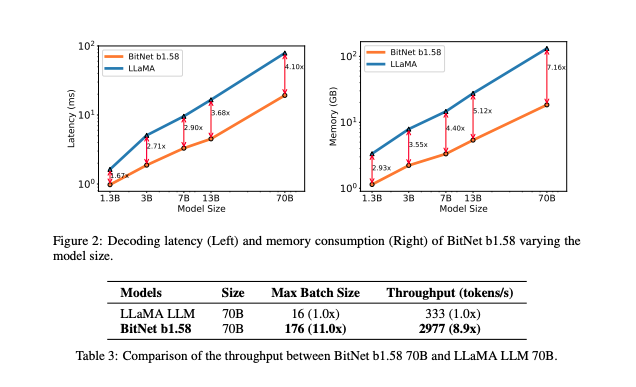
L’immagine mostra due grafici che confrontano la latenza di decodifica (a sinistra) e il consumo di memoria (a destra) tra BitNet b1.58 e LLaMA LLM variando la dimensione del modello. Nel grafico della latenza, BitNet b1.58 mostra una riduzione significativa della latenza rispetto a LLaMA LLM all’aumentare della dimensione del modello. Similmente, il grafico della memoria dimostra che BitNet b1.58 utilizza meno memoria rispetto a LLaMA LLM, con il divario che aumenta man mano che la dimensione del modello cresce. La tabella sottostante fornisce un confronto del throughput tra BitNet b1.58 e LLaMA LLM con 70B di parametri, mostrando che BitNet b1.58 supporta una dimensione di batch massima molto più grande e un throughput (token al secondo) significativamente più alto rispetto a LLaMA LLM.
Hardware ad-hoc: ASICSs
Sembra sempre più plausibile lo sviluppo di elettronica specializzata come gli ASICs per la AI, ne abbiamo parlato qui.
Gli ASICs (Application-Specific Integrated Circuits) sono circuiti integrati progettati per uno scopo specifico, diversamente dai processori general purpose. Groq è una società che sviluppa hardware per accelerare operazioni di machine learning, offrendo soluzioni che potrebbero beneficiare enormemente dall’efficienza dei modelli a 1 bit. Queste tecnologie giocano un ruolo cruciale nell’ottimizzare le prestazioni e ridurre il consumo energetico di complessi calcoli di intelligenza artificiale.
Referenza bibliografica
Ma, Shuming, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. “The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits.” arXiv preprint arXiv:2402.17764 (2024).