Large Language Models (LLM): pre-training, fine-tuning o prompt engineering
Il costo di training per i modelli LLM si misura in petaflop/s day (PFSD) che poi significa 86400e15 operazioni FLOP. Per fare 1 PFSD ci vogliono 8 Nvidia v100s, oppure 2 Nvidia A100 che si trovano su Amazon a circa $8000 l’una.
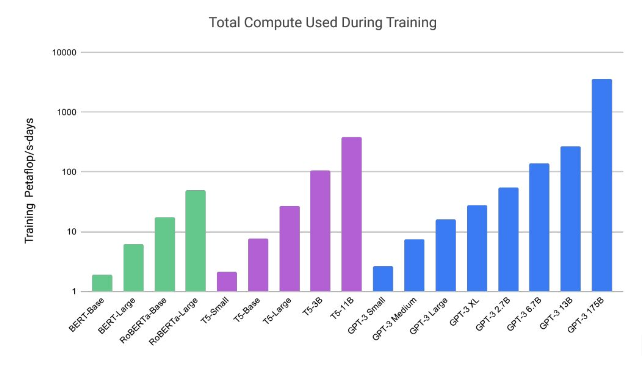
Questo grafico estratto da [1] ci da un’idea del numero di operazioni necessarie, senza entrare del merito del costo operativo reale che naturalmente è sicuramente superiore a quello del semplice hardware.
[1] Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
Pre-trainng di un modello LLM
Fondamentalmente, un Modello di Linguaggio di Grande Dimensione (LLM) mira a prevedere la parola successiva in una sequenza basandosi sulle parole che la precedono. L’addestramento preliminare è la fase iniziale in cui addestriamo l’LLM a prevedere questa parola successiva con maggiore accuratezza. È come insegnare al modello le sfumature del linguaggio prima di perfezionarlo per compiti specifici.